


امروزه با توجه به اینکه حجم دادههای جمعآوری شده از دستگاههای هوشمند در حال رشد است و مقررات بیشتری نیز مربوط به محافظت از حریم خصوصی در حال اجرا است، (FL (Federation learning راهکاری برای به حداکثر رساندن مزایای استفاده از دادههای بزرگ (Big Data) ارائه میدهد به صورتیکه دادههای حساس به صورت محلی و به اشتراک گذاشته نشده حفظ میشود.
امروزه با توجه به اینکه حجم دادههای جمعآوری شده از دستگاههای هوشمند در حال رشد است و مقررات بیشتری نیز مربوط به محافظت از حریم خصوصی در حال اجرا است، (FL (Federation learning راهکاری برای به حداکثر رساندن مزایای استفاده از دادههای بزرگ (Big Data) ارائه میدهد به صورتیکه دادههای حساس به صورت محلی و به اشتراک گذاشته نشده حفظ میشود.
شما چگونه الگوریتم یادگیری یک ماشین را توسعه میدهید وقتی که از مجموعه دادههای جداگانه که امکان به اشتراک گذاری بین سازمانها و حتی مکانها را ندارد استفاده میکنید. این مدلی هست که FL قصد دارد آن را حل کند.
این تکنولوژی در حال حاضر توسط بسیاری از سازمانها برای آموزش الگوریتمهای خود بر روی چندین مجموعه دادهای مجزا بدون مبادله داده بین آنها مورد استفاده قرار گرفته است.
طی دو دهه گذشته، تحقیقات در مورد یادگیری ماشینی (Machine Learning) منجر به موفقیت قابل توجهی در زمینههایی هچون: مراقبتهای بهداشتی دیجیتال ، پیشبینی آبوهوا، کشاورزی، مدیریت ترافیک، تدارکات، امنیت و بسیاری دیگر شده است. برای کنترل این چنین فعالیتهای پیچیده، الگوریتمهای یادگیری ماشینی (ML) به صورت پیوسته در حال یادگیری از مجموعه دادههای عظیم جمعآوری شده از تمام دنیا هستند. با این وجود، این مجموعه دادهها میتوانند حاوی اطلاعاتی خصوصی، محرمانه یا حساس باشند. علاوه بر این، استفاده از مجموعه دادهای مجزا (بدون مبادله داده) میتواند منجر به پردازش نادرست دادهها شود که متعاقباً باعث بروز مشکلات آماری و فنی در پیشبینیها خواهد شد و نهایتاً به شدت روی دقت نتایج برای یک کاربری یا مکان خاص تأثیر منفی داشته باشد.
نیاز به استفاده از مجموعه دادههای بزرگ برای گسترش هوش مصنوعی (AI) باعث بوجود آمدن رویکردها و تحقیقات مختلفی برای دستیابی به دادهها از چندین سایت و سازمان شده است. بسیاری از این ابتکارات در درجه اول روی ایجاد دریاچههای داده متمرکز شدهاند. این موارد عمدتاً در زمینههایی همچون افزایش ارزش تجاری دادهها و یا کمک به دانشمندان در تحقیقات بکار گرفته میشود.
با این وجود، دریاچههای داده هنوز چالشهای مهمی در زمینه حریم خصوصی و امنیت اطلاعات به وجود میآورند به گونهای که ناشناس ماندن، کنترل دسترسی و انتقال ایمن دادهها اغلب کاری غیرممکن است. تکنولوژی FL در واقع برای رفع این چالشهاو با هدف حفظ ایمن دادهها بدون به اشتراکگذاری آنها، بوجود آمده است.الگوریتمهایی که روی مجموعه دادههای FL کار میکنند از دادههای غیر هم مکان (non co-located data) تغذیه میشوند و یاد میگیرند.هر کنترل کننده داده یک سازمان یا سایت فرایندها و ملاحظات مربوط به حریم خصوصی خود را تعریف میکند.
به عنوان مثال یک شرکت چند ملیتی با مراکز داده در کشورها یا مناطق مختلف ممکن است قوانین متفاوتی برای مدیریت حریم خصوصی دادهها داشته باشد.بعلاوه، برخی از سازمانها نیز ترجیح میدهند برخی از دادهها را هرگز از دیتاسنتر فیزیکی یا محلی (local)خود را خارج نکنند و بیرون از سازمان موردنظر به اشتراک گذاشته نشوند.برای استفاده از این دادهها در کاربردهای هوش مصنوعی (AI)، آنها باید بتوانند الگوریتمهای یادگیری ماشینی (Machine Learning) را به صورت محلی(local) اجرا کنند و نتایج را بدون انتقال دادههای اصلی تلفیق کنند.
هدف اصلی تکنولوژیFL تلفیق دانش چندین سیلوی داده موجود در نهادها و مکانهای شرکت کننده در یک مدل جهانی است. در FL هر شرکت کننده با استفاده از چندین فرایند تکراری بهینهسازی روی دادهها، از مجموعه داده خود برای بدست آوردن و اصلاح نتایج پردازش دادهها در سطح جهانی استفاده میکند.سپس پارامترهای به روز شده را با سایر شرکت کنندگان به اشتراک میگذارد. روند واقعی این فرایند به توپولوژی شبکه FL بستگی دارد زیرا گرهها به دلیل محدودیتهای جغرافیایی یا نظارتی ممکن است به زیر شبکهها نفوذ کنند.
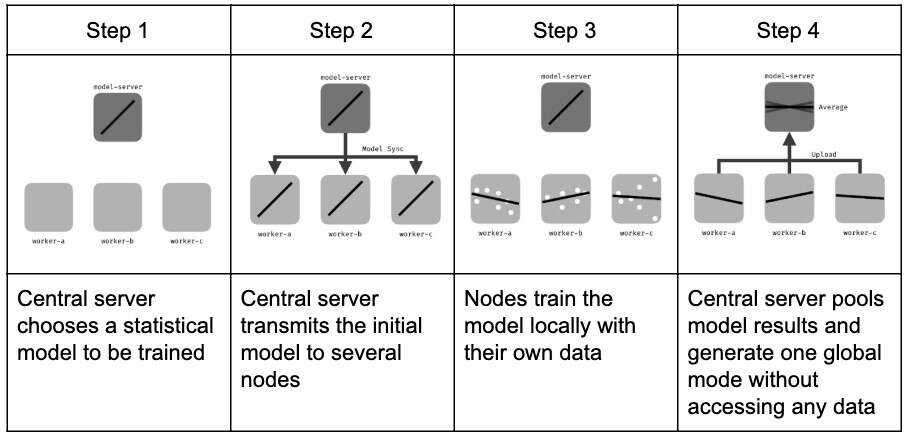
این تکنولوژی به ارتباط مکرر بین گرهها نیاز داردبنابراین برای تبادل پارامترهای مدل یادگیری ماشینی (ML) ، نیاز به قدرت پردازش لوکال و حافظه کافی و همچنین شبکههای پرسرعت وجود دارد.علاوه بر این، این فناوری همچنین از برقراری ارتباط مستقیم بین دادهها که برای شروع یادگیری متمرکز ماشین نیاز به منابع قابل توجهی دارد اجتناب میکند.
تکنولوژی FL یک روش مؤثر برای دستیابی به مدلهای قدرتمند، دقیق، ایمن، قوی و بیطرفانه است و مزیت اصلی آن اطمینان از حریم خصوصی یا مخفی بودن دادهها است. این فناوری نه تنها به انطباق با موج جدید مقررات حریم خصوصی و امنیتی دولت کمک میکند بلکه چون دادههای لوکال (محلی) رد و بدل نمیشوند، هک کردن آن به شدت غیرممکن به نظر میرسد.
